单线程备份文件扫描
脚本
import requests
import re
# 使用方法:
# 在这个路径添加 D:\Desktop\url.txt url.txt 的文件 在文件中添加带 http:// 或者 https:// 的域名,一行一个
# 将13和15行中的 D:\Desktop\url.txt 改为 url.txt 即可读取脚本目录下的 url.txt 文件内容
proxy = {"http": "127.0.0.1:8080"} #代理
## inurl 定义要扫的备份文件
inurl = {"/www.zip","/www.rar","/www.tar.gz","/wwwroot.zip","/wwwroot.rar","/wwwroot.tar.gz","/web.zip","/web.rar","/web.tar.gz","/.svn"}
hz = {".zip",".rar",".tar.gz"} # 指定备份文件后缀 后面自动生成为 xxx.com.zip 样式的格式
count = len(open(r'D:\Desktop\url.txt', 'r').readlines())
count = count * 13 # inurl + hz 的总和
with open(r"D:\Desktop\url.txt") as f:
n = 0
data = []
nodata = []
for line in f:
line = line.replace("\n","").split()
try:
for x in line:
for s in list(inurl):
url = x + s
n = n+1
html = requests.get(url,allow_redirects=False)
html.encoding = 'utf-8'
html = html.status_code
if html == 200 :
data.append(url)
print('进程:(%s/%s) ----- 状态:%s ----- 文件存在 ----- 目标:%s'%(n,count,html,url) )
else:
print('进程:(%s/%s) ----- 状态:%s ----- 不存在 ----- 目标:%s'%(n,count,html,url) )
if x.startswith("https://"):
for index in hz:
url = x + '/' + x.replace("https://","") + index
n = n+1
html = requests.get(url,allow_redirects=False)
html.encoding = 'utf-8'
html = html.status_code
if html == 200 :
data.append(url)
print('进程:(%s/%s) ----- 状态:%s ----- 文件存在 ----- 目标:%s'%(n,count,html,url) )
else:
print('进程:(%s/%s) ----- 状态:%s ----- 不存在 ----- 目标:%s'%(n,count,html,url) )
elif x.startswith("http://"):
for index in hz:
url = x + '/' + x.replace("http://","") + index
n = n+1
html = requests.get(url,allow_redirects=False)
html.encoding = 'utf-8'
html = html.status_code
if html == 200 :
data.append(url)
print('进程:(%s/%s) ----- 状态:%s ----- 文件存在 ----- 目标:%s'%(n,count,html,url) )
else:
print('进程:(%s/%s) ----- 状态:%s ----- 不存在 ----- 目标:%s'%(n,count,html,url) )
except:
nodata.append(url)
print('进程:(%s/%s) ----- 状态:%s ----- 无法访问 ----- 目标:%s'%(count,n,html,url) )
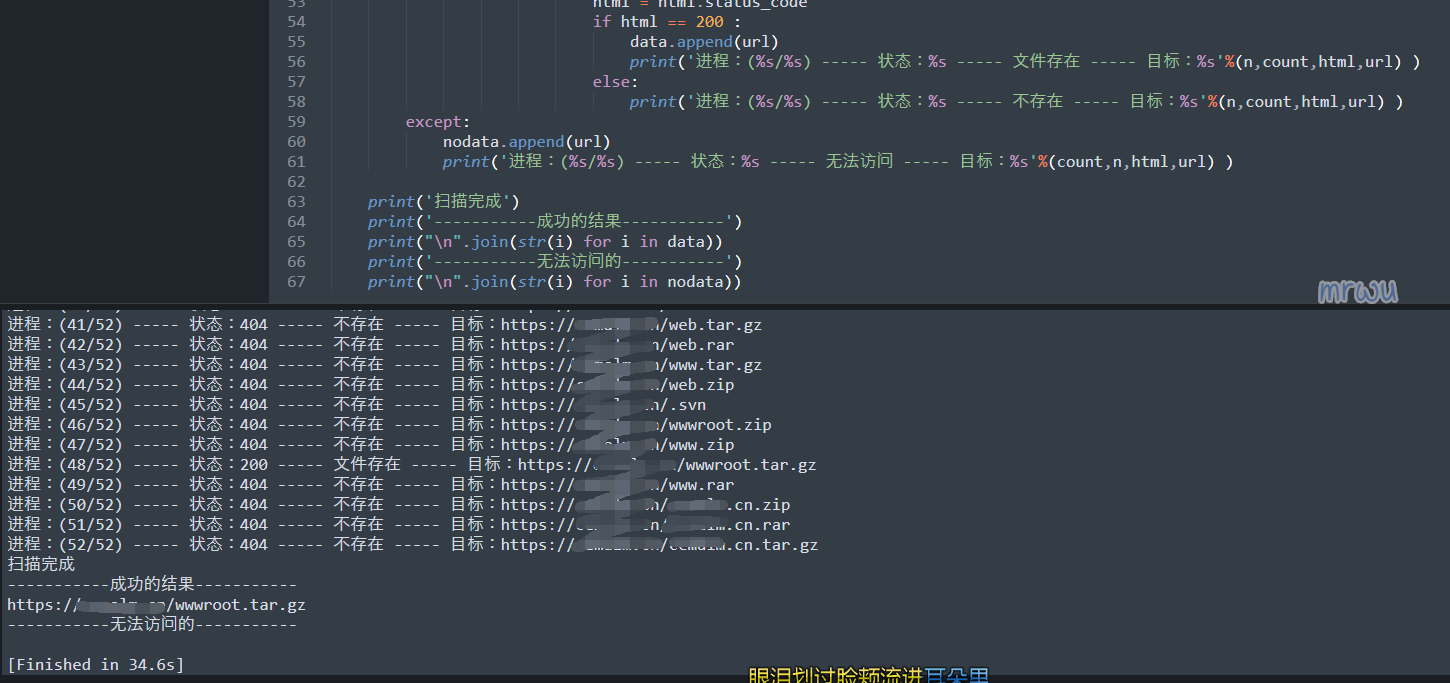
print('扫描完成')
print('-----------成功的结果-----------')
print("\n".join(str(i) for i in data))
print('-----------无法访问的-----------')
print("\n".join(str(i) for i in nodata))说明
常见的备份文件命名如下: www.zip www.rar www.tar.gz wwwroot.zip wwwroot.rar wwwroot.tar.gz web.zip web.rar web.tar.gz .svn 本脚本的作用是扫描如上备份文件以及带域名的备份文件(www.xx.com/www.xx.com.zip等)是否存在,喜欢的可以收藏~多线程备份文件扫描
脚本
# -*- coding: utf-8 -*-
# @Author: mrwu
# @Date: 2022-03-07 09:43:19
# @Last Modified by: mrwu
# @Last Modified time: 2023-02-08 17:23:53
from queue import Queue
from tqdm import tqdm
import requests
import re
import argparse
import threading
requests.packages.urllib3.disable_warnings() #关闭ssl控制台报错
header = {"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1"}
## 定义要扫的备份文件
inurl = {"www","wwwroot","web","备份","源码"}
hz = {".zip",".rar",".tar.gz",".7z",".tar",".bz2",".xz"}
urllist = []
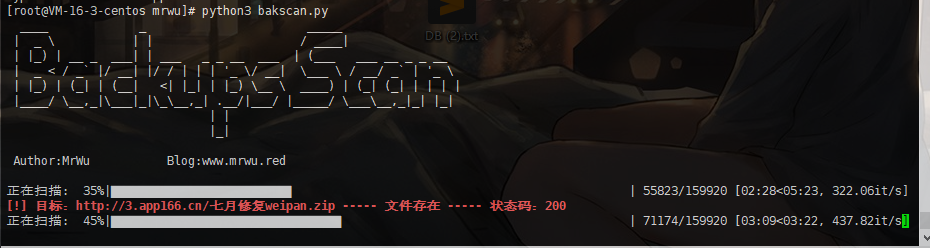
def banner():
print(''' ____ _ _____
| _ \ | | / ____|
| |_) | __ _ ___| | ___ _ _ __ ___ | (___ ___ __ _ _ __
| _ < / _` |/ __| |/ / | | | '_ \/ __| \___ \ / __/ _` | '_ \
| |_) | (_| | (__| <| |_| | |_) \__ \ ____) | (_| (_| | | | |
|____/ \__,_|\___|_|\_\\__,_| .__/|___/ |_____/ \___\__,_|_| |_|
| |
|_|
Author:MrWu Blog:www.mrwu.red
''')
def save(data):
f = open(r'fail_url.txt', 'a',encoding='utf-8')
f.write(data + '\n')
f.close()
def open_url(url):
with open(url) as f:
for url in f:
domain = url.replace("\n","").replace("http://","").replace("https://","")
for y in hz:
urllist.append(url.replace("\n","")+"/"+domain+y)
for x in inurl:
urllist.append(url.replace("\n","")+"/"+x+y)
return(urllist)
def run(url):
try:
res = requests.get(url, headers=header, stream=True, verify=False, timeout=4)
ctype = res.headers['Content-Type']
ctype = ctype.lower()
if ctype.find('application'):
res.close()
else:
res.close()
tqdm.write("[!] 文件存在 类型:%s 地址:%s"%(ctype,url))
except:
save(url)
def burst():
while not txt.empty():
pbar.set_description("")
pbar.update(1)
run(txt.get())
if __name__ == '__main__':
banner()
parser = argparse.ArgumentParser()
parser.add_argument('-u','--url', default='url.txt',help="URL文件路径")
parser.add_argument('-t','--threads', default='60',help="进程数,不要超过60")
args = parser.parse_args()
txt = Queue()
for x in open_url(args.url):
txt.put(x)
threads = []
pbar = tqdm(total=txt.qsize(), desc='开始扫描',colour='#00ff00', position=0, ncols=90)
for i in range(int(args.threads)):
t = threading.Thread(target = burst)
t.start()
threads.append(t)
for t in threads:
t.join()
tqdm.write("[ok] 全部任务已结束!")说明
- -u 参数指定要扫描的url字典文件路径,默认脚本文件目录下的 url.txt 文件,一行一个
- -t 参数指定扫描的进程数,默认20,不要超过60,进程太高可能导致扫描不准确
- URL.txt 文件中的URL地址一定得带协议头,如:https://www.baidu.com 否则会报错
- 无法访问的URL地址会自动存放到脚本目录下的 fail_url.txt 文件中
- 如果需要增加备份文件字典关键词,修改代码17行中的 inurl 变量,在其中增加你需要的关键词
- 感觉用不到代理,所以就没写代理功能
- 扫描成功的结果是实时显示
- 用到的模块:
Pooltqdmrequestsargparse自行安装