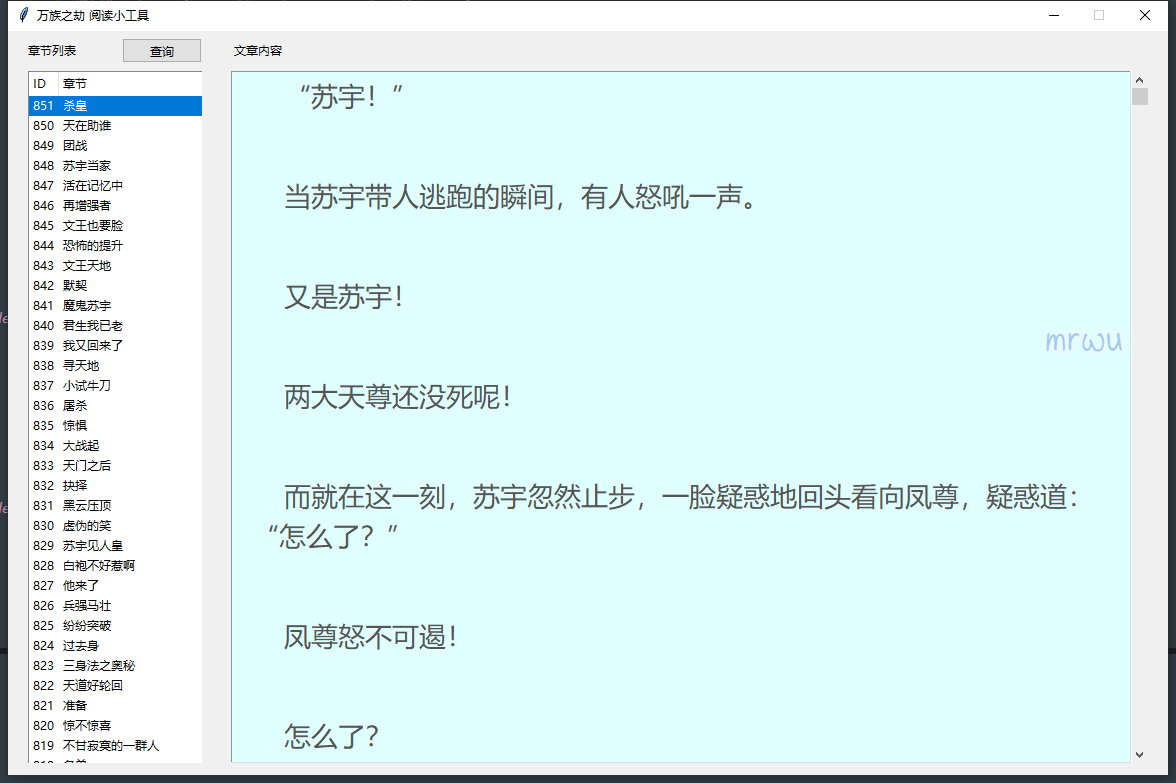
"""
小说阅读小工具
"""
import requests
from bs4 import BeautifulSoup
from string import digits
import re
import tkinter as tk
from tkinter import ttk
def treeview_sort_column(tv, col, reverse):#Treeview、列名、排列方式
l = [(tv.set(k, col), k) for k in tv.get_children('')]
l.reverse()#排序方式
for index, (val, k) in enumerate(l):#根据排序后索引移动
tv.move(k, '', index)
tv.heading(col, command=lambda: treeview_sort_column(tv, col, not reverse))#重写标题,使之成为再点倒序的标题
class PyWinDesign:
def __init__(self, 启动窗口):
self.启动窗口 = 启动窗口
self.启动窗口.title('万族之劫 阅读小工具')
self.启动窗口.resizable(width=False, height=False)
screenwidth = self.启动窗口.winfo_screenwidth()
screenheight = self.启动窗口.winfo_screenheight()
size = '%dx%d+%d+%d' % (1160, 744, (screenwidth - 1160) / 2, (screenheight - 744) / 2)
self.启动窗口.geometry(size)
self.超级列表框1 = ttk.Treeview(self.启动窗口,show='headings',columns=('ID','章节'))
self.超级列表框1.column('ID', width=30,anchor='w')
self.超级列表框1.column('章节', width=150,anchor='w')
self.超级列表框1.heading('ID', text='ID',anchor='w')
self.超级列表框1.heading('章节', text='章节',anchor='w')
self.超级列表框1.bind('<ButtonRelease-1>', self.表项单机)
self.超级列表框1.place(x=20,y=40,width=174,height=692)
self.编辑框1_滚动条_纵 = tk.Scrollbar(self.启动窗口)
self.编辑框1_滚动条_纵.place(x=1123,y=40,width=18,height=692)
self.编辑框1 = tk.Text(self.启动窗口,yscrollcommand=self.编辑框1_滚动条_纵.set,wrap=tk.WORD,bg='#E0FFFF',font=('微软雅黑', '20'),fg='#555',spacing1=5,spacing2=5,spacing3=10,padx=20,)
self.编辑框1_滚动条_纵.config(command=self.编辑框1.yview)
self.编辑框1.place(x=223,y=40,width=900,height=692)
self.标签1_标题 = tk.StringVar()
self.标签1_标题.set('章节列表')
self.标签1 = ttk.Label(self.启动窗口,textvariable=self.标签1_标题,anchor=tk.W)
self.标签1.place(x=18,y=8,width=80,height=24)
self.标签2_标题 = tk.StringVar()
self.标签2_标题.set('文章内容')
self.标签2 = tk.Label(self.启动窗口,textvariable=self.标签2_标题,anchor=tk.W)
self.标签2.place(x=223,y=8,width=80,height=24)
self.按钮1_标题 = tk.StringVar()
self.按钮1_标题.set('查询')
self.按钮1 = ttk.Button(self.启动窗口,textvariable=self.按钮1_标题,command=self.data_name)
self.按钮1.place(x=114,y=7,width=80,height=25)
def url_data(self):
url = 'http://www.biqudu.tv/0_698/'
html = requests.get(url)
html.encoding = 'utf-8' #python3版本中需要加入
#提取每章内容
html = re.findall('<dd><a href=(.*)>(.*)</a></dd>',html.text)
html =str(html)
return html
def data_name(self):
#提取章节名字
name = re.findall('章 [\u4e00-\u9fa5]+',self.url_data())
name ="".join(name)
name = name.replace("章","").split()
name = list(name)
uid = 0
for eachLine in name:
uid += 1
data = str(uid)+" "+eachLine
self.超级列表框1.insert('', 'end', values = [uid,eachLine])
treeview_sort_column(self.超级列表框1, 'ID', False)
def data_link(self):
#提取章节URL
link = re.findall('(?<=/).*?(?=")',self.url_data())
link ="".join(link)
link = link.replace("'","").split()
#提取章节名字
name = re.findall('章 [\u4e00-\u9fa5]+',self.url_data())
name ="".join(name)
name = name.replace("章","").split()
name = list(name)
links = zip(name,link)
return links
def 表项单机(self,event):
html = self.data_link()
html = dict(html)
item_text = []
for x in self.超级列表框1.selection():
item_text = self.超级列表框1.item(x,"values")
remove_digits = str.maketrans('', '', digits)
item_text = str(item_text)
item_text = item_text.translate(remove_digits)
item_text = str(item_text).replace("(","").replace(",","").replace(")","").replace("'","").replace(" ","")
#获取点击项目的名称然后根据项目名称得到地址
item_text = html[item_text]
url = 'http://www.biqudu.tv/'
urls = url+item_text
html = requests.get(urls)
html.encoding = 'utf-8' #python3版本中需要加入
html = html.text
html = BeautifulSoup(html, 'html.parser')
content = html.select("#content")
content = str(content).replace("<br />","\n").replace('[<div id="content">','').replace('<br/>','').replace('</div>]','')
self.编辑框1.delete(1.0,tk.END)
self.编辑框1.insert(tk.INSERT,content)
if __name__ == '__main__':
url_data = PyWinDesign.url_data
root = tk.Tk()
app = PyWinDesign(root)
root.mainloop()