用了好多年御剑了,越来越感觉御剑的乏力;
在渗透过程中,本机电脑对目标进行手工检测,但总因为御剑触发防火墙被拉IP,虽然有代理IP,但是总感觉不爽,另外即使没有防火墙,因为字典的日积月累导致御剑扫描速度真的越来越差劲,很少会跑完过,基本都是跑出来几条信息就关掉了,而且我电脑配置也低,用御剑老是卡死,总而言之言而总之,御剑的不更新已经被时代淘汰了。。。
很久前就想把御剑换掉,但是一直没遇到合适的,恰巧昨天看文章让我看到个目录扫描脚本还不错,测试了下,感觉很棒,于是有了本文。

-h, --help 查看帮助
-u URL, --url=URL 设置url
-L URLLIST, --url-list=URLLIST 设置url列表
-e EXTENSIONS, --extensions=EXTENSIONS 网站脚本类型
-w WORDLIST, --wordlist=WORDLIST 设置字典
-l, --lowercase 小写
-f, --force-extensions 强制扩展字典里的每个词条
-s DELAY, --delay=DELAY 设置请求之间的延时
-r, --recursive Bruteforce recursively 递归地扫描
--scan-subdir=SCANSUBDIRS, --scan-subdirs=SCANSUBDIRS 扫描给定的url的子目录(用逗号隔开)
--exclude-subdir=EXCLUDESUBDIRS, --exclude-subdirs=EXCLUDESUBDIRS 在递归过程中排除指定的子目录扫描(用逗号隔开)
-t THREADSCOUNT, --threads=THREADSCOUNT 设置扫描线程
-x EXCLUDESTATUSCODES, --exclude-status=EXCLUDESTATUSCODES 排除指定的网站状态码(用逗号隔开)
-c COOKIE, --cookie=COOKIE 设置cookie
--ua=USERAGENT, --user-agent=USERAGENT 设置用户代理
-F, --follow-redirects 跟随地址重定向扫描
-H HEADERS, --header=HEADERS 设置请求头
--random-agents, --random-user-agents 设置随机代理
--timeout=TIMEOUT 设置超时时间
--ip=IP 设置代理IP地址
--proxy=HTTPPROXY, --http-proxy=HTTPPROXY 设置http代理。例如127.0.0.1:8080
--max-retries=MAXRETRIES 设置最大的重试次数
-b, --request-by-hostname 通过主机名请求速度,默认通过IP
--simple-report=SIMPLEOUTPUTFILE 保存结果,发现的路径
--plain-text-report=PLAINTEXTOUTPUTFILE 保存结果,发现的路径和状态码
--json-report=JSONOUTPUTFILE 以json格式保存结果
下载地址
推荐理由
- 速度快,不会出现什么卡死跑不完字典的情况。
- 该有的功能基本都有,不过如果能加上一个中断继续的功能就更完美了。
- 不用放本地,不会再影响自己电脑的卡顿,直接放阿里云的机子上面跑。(听说阿里云机子扫阿里云不会被墙!)
- 其他的不多说了,自己测试才知道是否适合自己,反正我感觉很 good。
建议
/db/dicc.txt 文件是工具自带的字典,虽然工具可以指定自定义字典,但是多个字典,每个字典指定一次扫一次不累么?所以我将所有的字典,比如御剑以脚本语言区分的字典,我全部合并为一个,然后去掉重复,在替换掉 /db/dicc.txt 文件,就能免除每次指定自己字典的尴尬麻烦。
虽然全部合并一个会大大的影响扫描速度,比如 PHP 的站点,却非要去扫一堆 aspx\asp\jsp 的字典有些尴尬,但是不可否认,速度真的很快,反正比我之前用御剑好太多了,所以可以忽略掉这点时间。
这里附上 2 条字典 Linux 下整理字典命令:
type *.txt > /root/1.txt //合并当前目录下的所有 txt 文件内容到 1.txt cat 1.txt|sort|uniq > 2.txt //去掉 1.txt 的重复内容并写入到 2.txt
另外,不要在意我图片中的 scan 命令,那是因为我嫌麻烦,改了个短的超链接
还有就是,这个工具需要 python 3.x 版本才行,如果你正好装了 sqlmap 那么 python 版本或许会起冲突。
sqlmap 明明说支持 3.x 但是我用不了,所以不得不装了2个版本的 python
最后在补充附赠个小脚本:
1.发现有些字典开头并没有 "/" 这也就导致如果出现2行一样的内容,一行有 "/" 开头,一行没有,那么去重复命令将不会去掉这样的。
2.另外不知道你们发现没有,反正我有遇到过,或许是保存时候没注意吧,中文报错编码出问题导致字典中有许多乱码,比如:
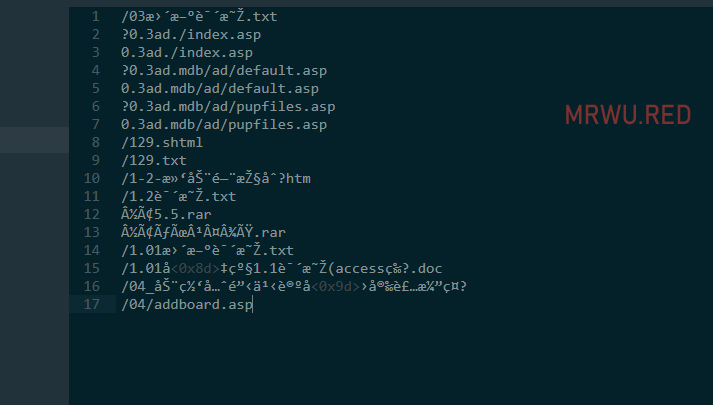
遇到上面2个问题,就需要下面这个小脚本了(可能需要安装 chardet 包):
#coding=utf-8
import chardet
def luanma(word):
f_charInfo = chardet.detect(word)
if(f_charInfo['encoding'] == 'utf-8'):
return True
return False
f=open('1.txt')
lines=f.readlines()
list=[]
for rs in lines:
if(rs.startswith('/')):
newWorld = rs
else:
newWorld = '/' + rs
if(not (luanma(newWorld))):
list.append(newWorld)
f.close()
output=open('output.txt','a')
for word in list:
output.write(word)
output.close()
本文作者为Mr.Wu,转载请注明,尊守博主劳动成果!
由于经常折腾代码,可能会导致个别文章内容显示错位或者别的 BUG 影响阅读; 如发现请在该文章下留言告知于我,thank you !

妈了个比 就是有你们这种拉鸡才会导致那么多站长的小主机一直被耗尽资源宕机,一个小博客那么小的cpu被扫描几秒就挂了,真是渣滓
@test第一,没有我们这些做测试的,互联网安全如何提升?如何让你们网络更有保障?
第二,看清楚软件,软件是指定目标站的扫描方式,用于已授权的目标站进行的安全测试使用,并不是你说的那些未授权的批量一通乱扫软件.
第三,即使是网上那些批量扫描软件,也是有办法杜绝的,自己技术渣,自己不反思,自己不采取行动去解决问题,来我这里闹你妈了个比.
不是只有你会骂脏话,不爱看衮.逗比
@Mr.Wu哈哈哈哈~6
@Mr.Wu想问一下博主可以分享代理ip吗,想要收集一下
友链友链哈哈。
http://xxxyz.xyz/
@哈哈哈[aru_2][aru_2]
@Mr.Wu刚买了个域名,不知道 转到哪儿,转到你这里免费给你打广告。
@Mr.Wu8元域名哈哈